According to the latest data from the Altcoin Season Index, the market is currently far from the threshold required to trigger a systemic rotation of capital. A reading above 75 is generally accepted as the benchmark for a true altseason; however, the index has remained well below this level for 256 consecutive days. This prolonged period of Bitcoin dominance underscores a fundamental shift in market dynamics, where institutional capital remains concentrated in the largest, most liquid digital asset, often at the expense of smaller-cap projects.
The Liquidity Constraint and the "Trophy Asset" Theory
The primary headwind facing the altcoin market is the absence of significant monetary easing. In previous cycles, particularly the 2020-2021 bull run, aggressive stimulus measures and low interest rates provided an abundance of global liquidity. This "cheap money" flowed down the risk curve, moving from Bitcoin into Ethereum and eventually into micro-cap altcoins.
In a recent market assessment, prominent trader "Crypto Kid" characterized altcoins as "trophy assets." This analogy suggests that most altcoins function similarly to luxury goods or high-end collectibles—assets that attract meaningful capital only when investors have significant surplus liquidity. Under the current regime of tighter monetary policy and high interest rates, the risk appetite required to fuel a broad altcoin rally is notably absent.
"Altcoins are the Ferrari of the investment world," the analyst noted. "When everyone is flush with cash, they buy the Ferrari. When conditions tighten, they stick to the gold bars. In this market, Bitcoin is the gold bar." This perspective suggests that until central banks pivot toward more aggressive rate cuts and quantitative easing, the capital necessary to lift the entire altcoin sector simultaneously will likely remain on the sidelines.
The Impact of Market Saturation and Token Proliferation
A critical factor contributing to the delay of altseason is the sheer volume of new tokens entering the market. In the 2017 bull cycle, there were approximately 3,000 active cryptocurrencies. Today, that number has ballooned into the tens of millions, driven largely by the ease of token creation on networks like Solana, Base, and various Ethereum Layer-2 solutions.
This proliferation has led to severe capital dilution. In previous years, new capital entering the crypto space was concentrated among a few dozen high-quality projects. Today, that same capital is spread across a vast ocean of "memecoins," utility tokens, and governance assets. Consequently, even when billions of dollars flow into the "altcoin" category, the impact on individual prices is muted because the liquidity is spread too thin.
Industry experts suggest that this dilution makes a 2017-style "rising tide lifts all boats" scenario increasingly unlikely. Instead, the market is shifting toward a "winner-takes-most" model where only a handful of projects within specific high-performing niches see substantial gains.
Narrative-Driven Pockets of Growth: AI, RWA, and DePIN
While the broad Altcoin Season Index sits at a modest 48/100—well below its yearly high of 78 recorded in September 2025—traders like "Player1Taco" emphasize that money is still being made in specific sectors. The market has transitioned from a general rally to a "narrative-driven" environment where attention is the most valuable currency.
Currently, the Artificial Intelligence (AI) sector remains the dominant focus for speculative capital. Projects that integrate blockchain with AI processing, data verification, or decentralized GPU power have significantly outperformed the broader market. The trader highlighted Venice (VVV) as a primary example of a project capturing market attention through its unique value proposition in the AI space.
Beyond AI, two other sectors have shown resilience:

- Real-World Assets (RWA): The tokenization of physical assets, including real estate, treasury bonds, and collectibles, continues to gain institutional interest. By bringing off-chain assets onto the blockchain, these projects offer a level of utility and stability that purely speculative tokens lack.
- Decentralized Physical Infrastructure Networks (DePIN): This sector is gaining traction by overlapping with both AI and RWA themes. Projects like Helium (HNT) and World Mobile (WMT) are building decentralized telecommunications and data center networks. By leveraging token incentives to build physical infrastructure, these projects provide a tangible bridge between the digital and physical economies.
A Chronology of Market Cycles and the 2028 Projection
The history of altcoin seasons provides a roadmap for current expectations. Historically, these periods of outperformance follow a specific sequence:
- Phase 1: Bitcoin leads the market higher as the "safe haven" asset.
- Phase 2: Ethereum begins to outperform Bitcoin as investors seek higher returns.
- Phase 3: Large-cap altcoins (the top 20) see significant inflows.
- Phase 4: "Full Altseason," where capital flows into mid-cap and small-cap tokens regardless of fundamentals.
The current cycle has seen a breakdown in this sequence. While Bitcoin has reached new heights, the transition to Phase 2 and 3 has been stuttered and inconsistent. This has led some analysts, including Crypto Kid, to project a much longer timeframe for the next true altseason, potentially pushing the window as far out as 2028 or 2029. This long-term view accounts for the time needed for the global economy to enter a new cycle of expansion and for the current glut of tokens to be "flushed out" through market consolidation.
Performance Analysis of Major Altcoins
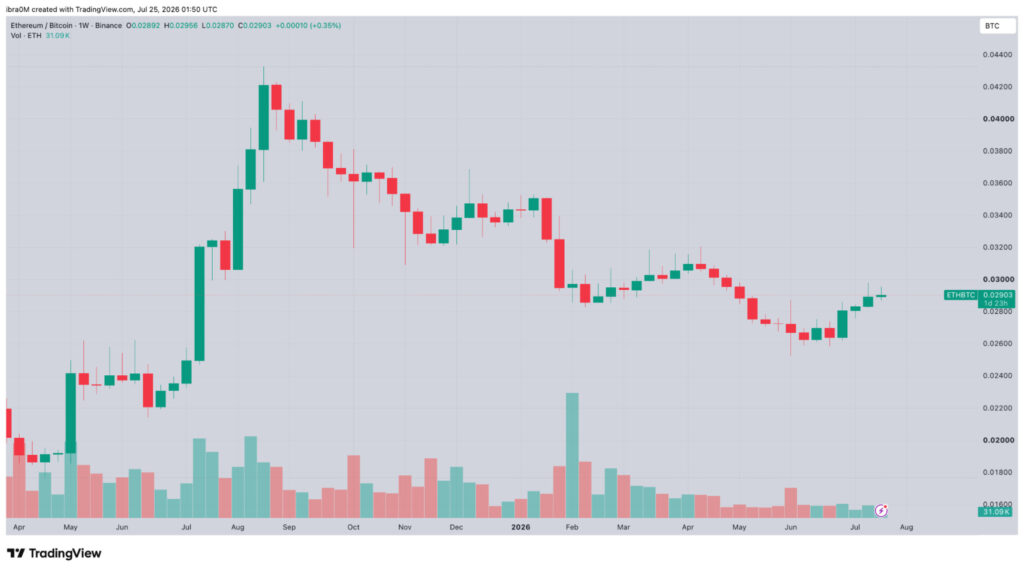
The lack of momentum is evident in the recent price action of the market’s largest non-Bitcoin assets. Ethereum (ETH), the traditional leader of altcoin rallies, recently traded at $1,793, representing a 1.45% decline over the short term. Despite its foundational role in the ecosystem, ETH has struggled to maintain its "ultrasound money" narrative in the face of competition from faster, cheaper Layer-1 blockchains.
Binance Coin (BNB) has shown relative strength compared to its peers, dropping 2.23% to $606. Its valuation remains supported by the massive ecosystem of the Binance Smart Chain and consistent on-chain activity driven by Launchpool events and exchange utility. However, it remains tethered to the broader market sentiment.
XRP, on the other hand, has faced more significant headwinds. The token fell 4.03% to $1.21 following a technical breakdown. After a period of bullish anticipation regarding regulatory clarity in the United States, XRP has succumbed to bearish pressure as traders take profits and the lack of new liquidity prevents a sustained breakout above key resistance levels.
Institutional Influence and the "Bitcoin Spell"
The introduction of Spot Bitcoin ETFs has fundamentally changed the relationship between Bitcoin and altcoins. Institutional investors are now able to gain exposure to Bitcoin through traditional brokerage accounts, but this access does not yet extend to the vast majority of altcoins. This creates a "liquidity trap" where capital enters the crypto ecosystem via Bitcoin but remains there, rather than rotating into smaller assets.
Furthermore, the "Bitcoin Spell" refers to the psychological and algorithmic dominance the leading asset holds over the market. Most trading pairs are still denominated in BTC, and automated trading bots often sell altcoins the moment Bitcoin shows signs of volatility. This creates a feedback loop where altcoins suffer during Bitcoin’s downtrends but fail to keep pace during its uptrends, leading to the "bleeding" effect on the BTC/Altcoin exchange pairs.
Implications for Investors and the Road Ahead
The current market environment suggests that the "buy and hold" strategy for a diversified basket of altcoins may no longer be as effective as it was in 2017 or 2021. The fragmentation of the market requires a more surgical approach, focusing on sectors with genuine utility and strong narrative tailwinds.
For a true altseason to return, several conditions likely need to be met:
- Macroeconomic Pivot: A return to quantitative easing and lower interest rates to provide the necessary liquidity.
- Regulatory Clarity: Clearer guidelines for altcoins to encourage institutional investment beyond Bitcoin and Ethereum.
- Market Consolidation: A reduction in the rate of new token creation, allowing capital to concentrate in high-quality projects.
- Technological Breakthroughs: New "killer apps" in the DeFi, AI, or DePIN sectors that drive user adoption and demand for underlying tokens.
Until these conditions align, the market appears destined to remain under the "Bitcoin Spell," with altcoins serving as speculative vehicles for specific narratives rather than a unified asset class. While the Altcoin Season Index may see occasional spikes, the broad, market-wide euphoria of previous cycles remains a distant prospect for the foreseeable future. Investors are advised to remain cautious, focusing on fundamental value and sector-specific trends rather than waiting for a tide that may not rise for several years.